Confluent HTTP Sink Connector
The HTTP Sink Connector is data type agnostic and thus does not need a Kafka schema as well as supporting ClickHouse specific data types such as Maps and Arrays. This additional flexibility comes at a slight increase in configuration complexity.
Below we describe a simple installation, pulling messages from a single Kafka topic and inserting rows into a ClickHouse table.
The HTTP Connector is distributed under the Confluent Enterprise License.
Quick start steps
1. Gather your connection details
To connect to ClickHouse with HTTP(S) you need this information:
The HOST and PORT: typically, the port is 8443 when using TLS or 8123 when not using TLS.
The DATABASE NAME: out of the box, there is a database named
default, use the name of the database that you want to connect to.The USERNAME and PASSWORD: out of the box, the username is
default. Use the username appropriate for your use case.
The details for your ClickHouse Cloud service are available in the ClickHouse Cloud console. Select the service that you will connect to and click Connect:
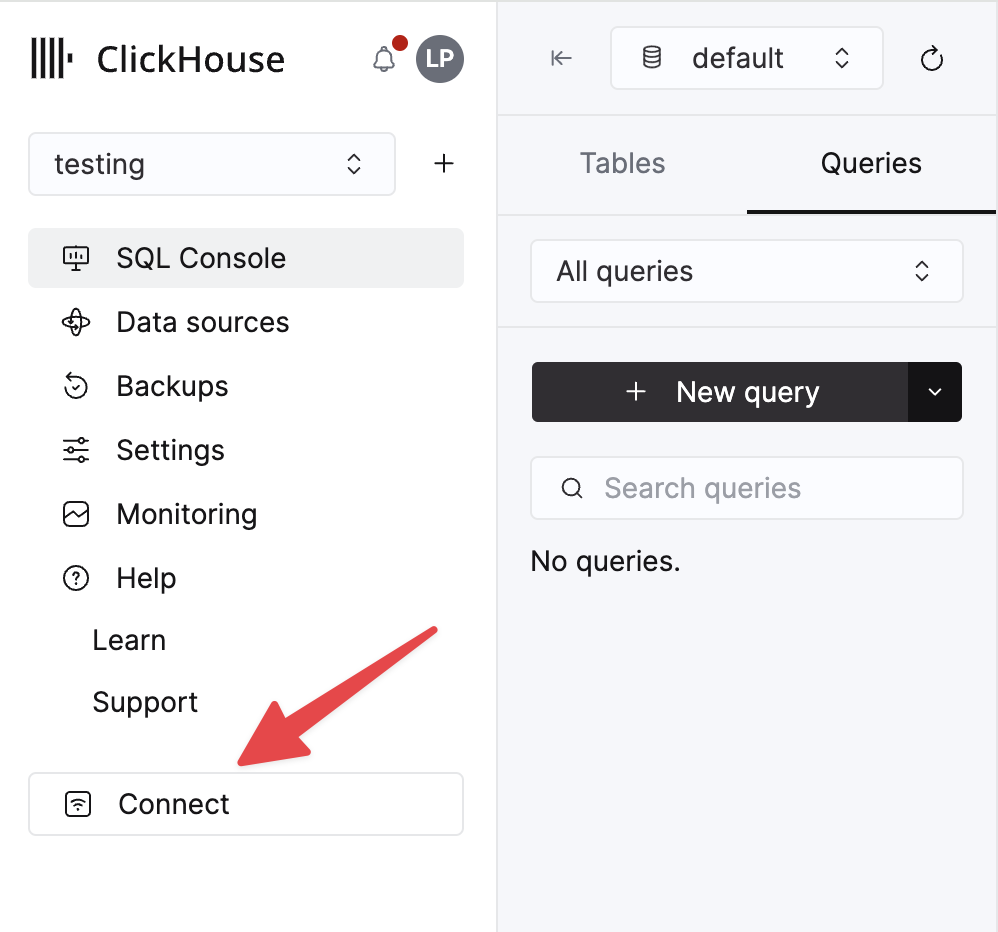
Choose HTTPS, and the details are available in an example curl command.
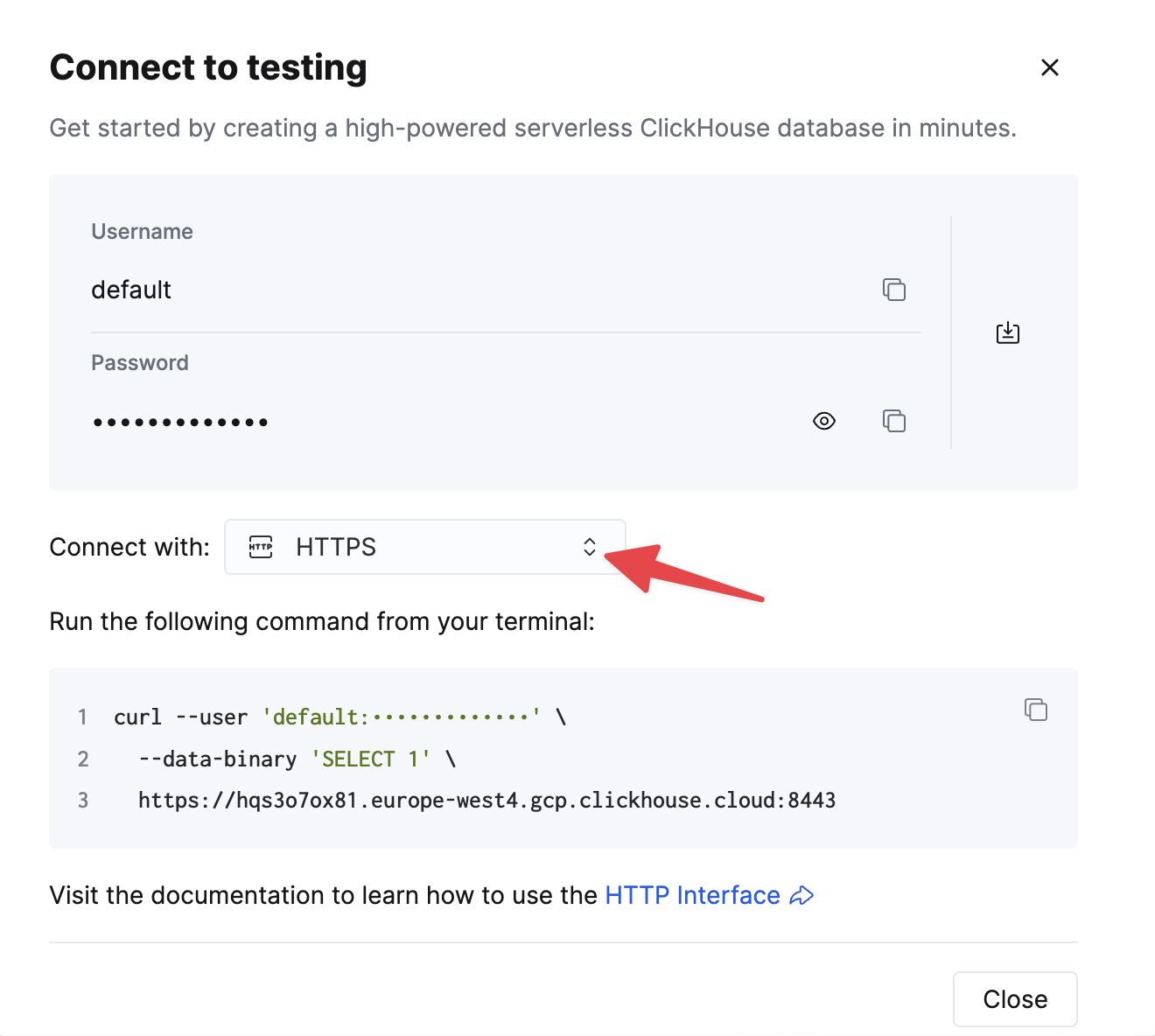
If you are using self-managed ClickHouse, the connection details are set by your ClickHouse administrator.
2. Run Kafka Connect and the HTTP Sink Connector
You have two options:
Self-managed: Download the Confluent package and install it locally. Follow the installation instructions for installing the connector as documented here. If you use the confluent-hub installation method, your local configuration files will be updated.
Confluent Cloud: A fully managed version of HTTP Sink is available for those using Confluent Cloud for their Kafka hosting. This requires your ClickHouse environment to be accessible from Confluent Cloud.
The following examples are using Confluent Cloud.
3. Create destination table in ClickHouse
Before the connectivity test, let's start by creating a test table in ClickHouse Cloud, this table will receive the data from Kafka:
CREATE TABLE default.my_table
(
`side` String,
`quantity` Int32,
`symbol` String,
`price` Int32,
`account` String,
`userid` String
)
ORDER BY tuple()
4. Configure HTTP Sink
Create a Kafka topic and an instance of HTTP Sink Connector:
Configure HTTP Sink Connector:
- Provide the topic name you created
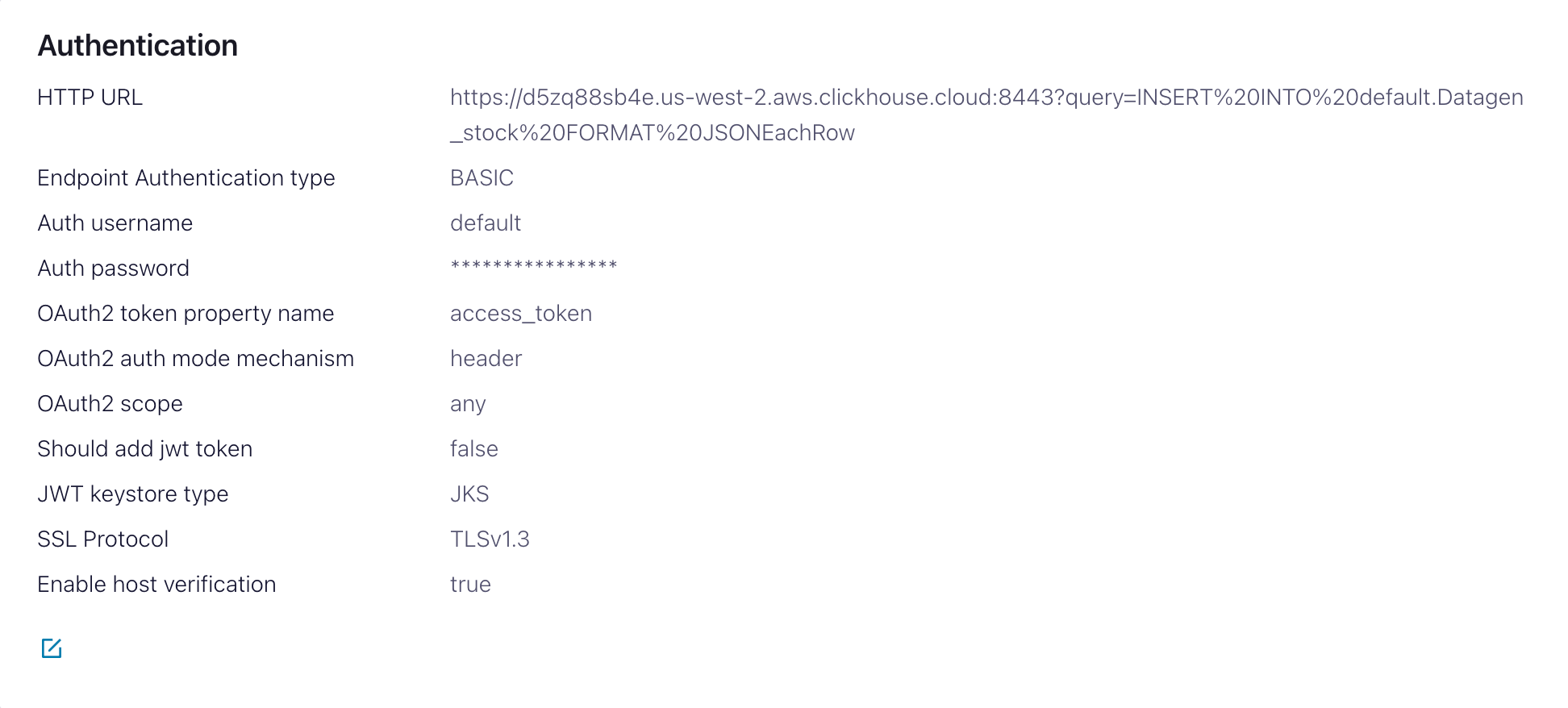
- Authentication
HTTP Url- ClickHouse Cloud URL with aINSERTquery specified<protocol>://<clickhouse_host>:<clickhouse_port>?query=INSERT%20INTO%20<database>.<table>%20FORMAT%20JSONEachRow. Note: the query must be encoded.Endpoint Authentication type- BASICAuth username- ClickHouse usernameAuth password- ClickHouse password
This HTTP Url is error-prone. Ensure escaping is precise to avoid issues.
- Configuration
Input Kafka record value formatDepends on your source data but in most cases JSON or Avro. We assumeJSONin the following settings.- In
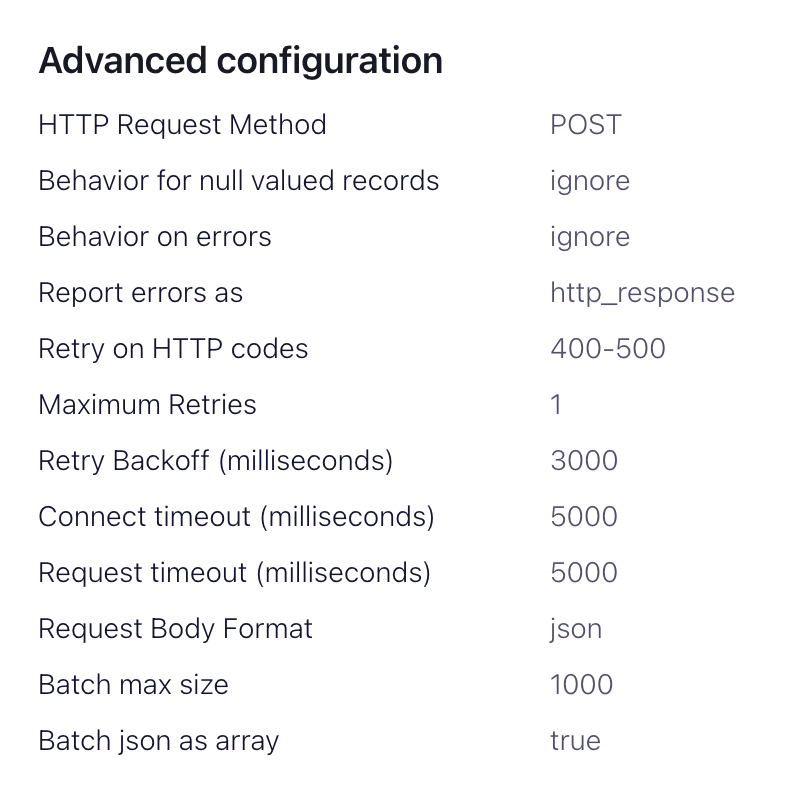
advanced configurationssection:HTTP Request Method- Set to POSTRequest Body Format- jsonBatch batch size- Per ClickHouse recommendations, set this to at least 1000.Batch json as array- trueRetry on HTTP codes- 400-500 but adapt as required e.g. this may change if you have an HTTP proxy in front of ClickHouse.Maximum Reties- the default (10) is appropriate but feel to adjust for more robust retries.
5. Testing the connectivity
Create an message in a topic configured by your HTTP Sink
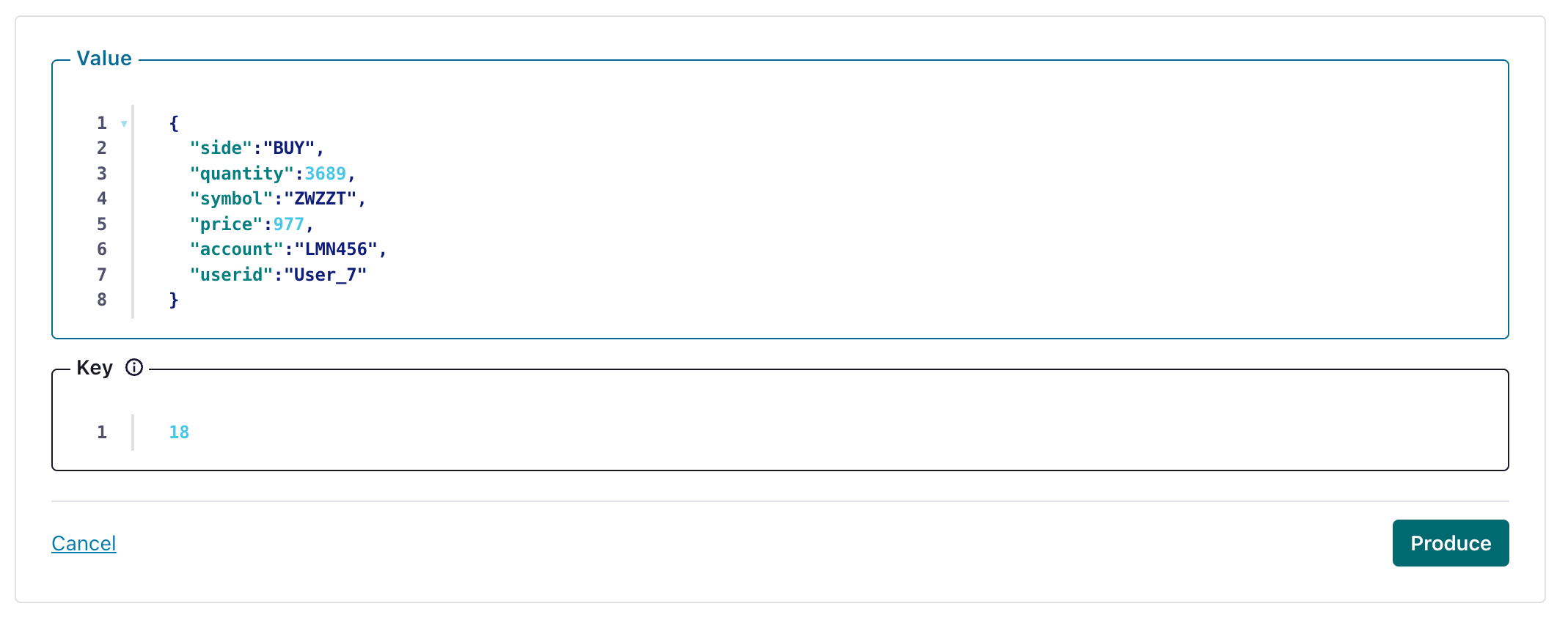
and verify the created message's been written to your ClickHouse instance.
Troubleshooting
HTTP Sink doesn't batch messages
From the Sink documentation:
The HTTP Sink connector does not batch requests for messages containing Kafka header values that are different.
- Verify your Kafka records have the same key.
- When you add parameters to the HTTP API URL, each record can result in a unique URL. For this reason, batching is disabled when using additional URL parameters.
400 Bad Request
CANNOT_PARSE_QUOTED_STRING
If HTTP Sink fails with the following message when inserting a JSON object into a String column:
Code: 26. DB::ParsingException: Cannot parse JSON string: expected opening quote: (while reading the value of key key_name): While executing JSONEachRowRowInputFormat: (at row 1). (CANNOT_PARSE_QUOTED_STRING)
Set input_format_json_read_objects_as_strings=1 setting in URL as encoded string SETTINGS%20input_format_json_read_objects_as_strings%3D1
Load the GitHub dataset (optional)
Note that this example preserves the Array fields of the Github dataset. We assume you have an empty github topic in the examples and use kcat for message insertion to Kafka.
1. Prepare Configuration
Follow these instructions for setting up Connect relevant to your installation type, noting the differences between a standalone and distributed cluster. If using Confluent Cloud, the distributed setup is relevant.
The most important parameter is the http.api.url. The HTTP interface for ClickHouse requires you to encode the INSERT statement as a parameter in the URL. This must include the format (JSONEachRow in this case) and target database. The format must be consistent with the Kafka data, which will be converted to a string in the HTTP payload. These parameters must be URL escaped. An example of this format for the Github dataset (assuming you are running ClickHouse locally) is shown below:
<protocol>://<clickhouse_host>:<clickhouse_port>?query=INSERT%20INTO%20<database>.<table>%20FORMAT%20JSONEachRow
http://localhost:8123?query=INSERT%20INTO%20default.github%20FORMAT%20JSONEachRow
The following additional parameters are relevant to using the HTTP Sink with ClickHouse. A complete parameter list can be found here:
request.method- Set to POSTretry.on.status.codes- Set to 400-500 to retry on any error codes. Refine based expected errors in data.request.body.format- In most cases this will be JSON.auth.type- Set to BASIC if you security with ClickHouse. Other ClickHouse compatible authentication mechanisms are not currently supported.ssl.enabled- set to true if using SSL.connection.user- username for ClickHouse.connection.password- password for ClickHouse.batch.max.size- The number of rows to send in a single batch. Ensure this set is to an appropriately large number. Per ClickHouse recommendations a value of 1000 is should be considered a minimum.tasks.max- The HTTP Sink connector supports running one or more tasks. This can be used to increase performance. Along with batch size this represents your primary means of improving performance.key.converter- set according to the types of your keys.value.converter- set based on the type of data on your topic. This data does not need a schema. The format here must be consistent with the FORMAT specified in the parameterhttp.api.url. The simplest here is to use JSON and the org.apache.kafka.connect.json.JsonConverter converter. Treating the value as a string, via the converter org.apache.kafka.connect.storage.StringConverter, is also possible - although this will require the user to extract a value in the insert statement using functions. Avro format is also supported in ClickHouse if using the io.confluent.connect.avro.AvroConverter converter.
A full list of settings, including how to configure a proxy, retries, and advanced SSL, can be found here.
Example configuration files for the Github sample data can be found here, assuming Connect is run in standalone mode and Kafka is hosted in Confluent Cloud.
2. Create the ClickHouse table
Ensure the table has been created. An example for a minimal github dataset using a standard MergeTree is shown below.
CREATE TABLE github
(
file_time DateTime,
event_type Enum('CommitCommentEvent' = 1, 'CreateEvent' = 2, 'DeleteEvent' = 3, 'ForkEvent' = 4,'GollumEvent' = 5, 'IssueCommentEvent' = 6, 'IssuesEvent' = 7, 'MemberEvent' = 8, 'PublicEvent' = 9, 'PullRequestEvent' = 10, 'PullRequestReviewCommentEvent' = 11, 'PushEvent' = 12, 'ReleaseEvent' = 13, 'SponsorshipEvent' = 14, 'WatchEvent' = 15, 'GistEvent' = 16, 'FollowEvent' = 17, 'DownloadEvent' = 18, 'PullRequestReviewEvent' = 19, 'ForkApplyEvent' = 20, 'Event' = 21, 'TeamAddEvent' = 22),
actor_login LowCardinality(String),
repo_name LowCardinality(String),
created_at DateTime,
updated_at DateTime,
action Enum('none' = 0, 'created' = 1, 'added' = 2, 'edited' = 3, 'deleted' = 4, 'opened' = 5, 'closed' = 6, 'reopened' = 7, 'assigned' = 8, 'unassigned' = 9, 'labeled' = 10, 'unlabeled' = 11, 'review_requested' = 12, 'review_request_removed' = 13, 'synchronize' = 14, 'started' = 15, 'published' = 16, 'update' = 17, 'create' = 18, 'fork' = 19, 'merged' = 20),
comment_id UInt64,
path String,
ref LowCardinality(String),
ref_type Enum('none' = 0, 'branch' = 1, 'tag' = 2, 'repository' = 3, 'unknown' = 4),
creator_user_login LowCardinality(String),
number UInt32,
title String,
labels Array(LowCardinality(String)),
state Enum('none' = 0, 'open' = 1, 'closed' = 2),
assignee LowCardinality(String),
assignees Array(LowCardinality(String)),
closed_at DateTime,
merged_at DateTime,
merge_commit_sha String,
requested_reviewers Array(LowCardinality(String)),
merged_by LowCardinality(String),
review_comments UInt32,
member_login LowCardinality(String)
) ENGINE = MergeTree ORDER BY (event_type, repo_name, created_at)
3. Add data to Kafka
Insert messages to Kafka. Below we use kcat to insert 10k messages.
head -n 10000 github_all_columns.ndjson | kcat -b <host>:<port> -X security.protocol=sasl_ssl -X sasl.mechanisms=PLAIN -X sasl.username=<username> -X sasl.password=<password> -t github
A simple read on the target table "Github" should confirm the insertion of data.
SELECT count() FROM default.github;
| count\(\) |
| :--- |
| 10000 |